텍스트 마이닝(Text mining)이란?
- 문자로 된 데이터에서 가치 있는 정보를 얻어 내는 분석 기법
텍스트 마이닝 과정
1. 형태소 분석(Morphology Analysis) - 문장을 구성하는 어절들이 어떤 품사로 되어 있는지 파악
2. 단어 빈도수 분석(TF_Term Frequency) - 형태소 분석으로 어절들의 품사를 파악한 후, '명사', '동사', '형용사' 등 의미를 지닌 품사의 단어를 추출해 각 단어가 얼마나 많이 등장했는지 확인 (명사, 동사 제일 의미 有)
3. 빈도표 만들기
4. 시각화
■ 텍스트 마이닝 준비하기
(1) 패키지 준비하기
- 한글 자연어 분석 패키지 <KoNLP(Korean Natural Language Processing)> 이용
- KoNLP는 자바(Java)가 설치되어 있어야 사용 가능. 사용 중인 OS에 맞는 파일을 다운로드해 설치할 것
자바 다운로드 https://www.java.com/ko/download/manual.jsp
모든 운영 체제용 Java 다운로드
모든 운영 체제용 Java 다운로드 권장 사항 Version 8 Update 211 릴리스 날짜: 2019년 4월 16일 Oracle Java 중요 라이센스 업데이트 Oracle Java 라이센스는 2019년 4월 16일 릴리스부터 변경되었습니다. 새로운 Oracle Java SE에 대한 Oracle Technology Network 라이센스 합의서는 이전 Oracle Java 라이센스와는 상당히 다릅니다. 새로운 라이센스는 개인 용도 및 개발 용도와 같
www.java.com
(참고: OS 버전은 [제어판] >> [시스템 및 보안] >> [시스템]의 '시스템 종류'에서 확인 가능)
(참고: 패키지를 로드했는데 에러 메시지가 출력된다면? - 포스팅 하단 참고)
(2) rJava, memoise 패키지 설치
- KoNLP를 사용하려면 rJava, memoise 패키지가 설치되어 있어야 함. 두 패키지를 먼저 설치한 후 KoNLP 설치
install.packages("rJava")
install.packages("memoise")
install.packages("KoNLP")
(3) dplyr 패키지 로드
- 설치가 완료되면 KoNLP와 전처리 작업에 사용할 dplyr을 로드
library(KoNLP)
library(dplyr)
(4) 사전 설정하기
- KoNLP에서 지원하는 NIA 사전은 98만여 개의 단어로 구성 (형태소 분석하는 데 이 사전 이용)
UseNIADic()
(5) 데이터 준비하기
- 깃허브(bit.ly/doit_rd)에서 hiphop.txt 파일을 다운로드해 프로젝트 폴더에 삽입 (텍스트 파일에는 멜론 차트 랩/힙합 부문 상위 50곡의 가사 있음)
- readLines()로 불러와 일부를 출력
- hiphop.txt는 아래와 같은 노래들의 가사로 구성되어 있음. 50위 전체 목록은 깃허브에 공유한 SongList.xlsx 파일에 있음.
# 데이터 불러오기
txt <- readLines("hiphop.txt")
head(txt)
## [1] "\"보고싶다" "이렇게 말하니까 더 보고 싶다"
## [3] "너희 사진을 보고 있어도" "보고 싶다"
## [5] "너무 야속한 시간" "나는 우리가 밉다"
(6) 특수문자 제거하기
- 문장에 이모티콘이나 특수문자가 포함되어 있으면 오류가 발생할 수 있음
- 문자 처리 패키지인 stringr의 str_replace_all()을 이용해 문장에 들어 있는 특수문자를 빈칸으로 수정
install.packages("stringr")
library(stringr)
# 특수문자 제거
txt <- str_replace_all(txt, "\\W", " ")(참고: str_replace_all()에 사용된 기호 \\W는 특수문자를 의미하는 '정규 표현식'. 정규 표현식을 이용하면 문장의 내용 중 이메일 주소, 전화 번호처럼 특정한 규칙으로 되어 있는 부분을 추출 가능)
■ 가장 많이 사용된 단어 알아보기
(1) 명사 추출하기
- KoNLP의 extractNoun()를 이용하면 문장에서 명사 추출 가능
- 명사를 보면 문장이 무엇에 대한 내용인지 파악 가능
extractNoun("대한민국의 영토는 한반도와 그 부속도서로 한다")
## [1] "대한민국" "영토" "한반도" "부속도서" "한"
(2) 빈도표 만들기
- 빈도표는 테이블(table) 형태이므로 다루기 쉽도록 데이터 프레임으로 변환하고 변수명을 수정
# 가사에서 명사 추출
nouns <- extractNoun(txt)
# 추출한 명사 list를 문자열 벡터로 변환, 단어별 빈도표 생성
wordcount <- table(unlist(nouns))
# 데이터 프레임으로 변환
df_word <- as.data.frame(wordcount, stringsAsFactors = F)
# 변수명 수정
df_word <- rename(df_word, word = Var1, freq = Freq)(참고: extractNoun()은 출력 결과를 리스트 형태로 반환. table(unlist(nouns))는 리스트로 되어 있는 nouns를 빈도 테이블로 변환하는 기능을 함.)
(3) 자주 사용된 단어 빈도표 만들기
- 한 글자로 된 단어는 의미가 없는 경우가 많기 때문에 nchar()를 이용해 두 글자 이상으로 된 단어만 추출
df_word <- filter(df_word, nchar(word) >= 2)
(4) 상위 20개 단어 추출
- 빈도 순으로 정렬한 후 상위 20개 단어 추출
top_20 <- df_word %>%
arrange(desc(freq)) %>%
head(20)
top_20
## word freq
## 1 you 89
## 2 my 86
## 3 YAH 80
## 4 on 76
## 5 하나 75
.
.
.- 텍스트가 힙합 가사이기 때문에 you, my, YAH 같은 영단어가 많이 사용됐다는 것을 알 수 있음
■ 워드 클라우드 만들기
워드 클라우드(Word cloud)란?
- 단어의 빈도를 구름 모양으로 표현한 그래프
- 단어의 빈도에 따라 글자의 크기와 색깔이 다르게 표현되기 때문에 어떤 단어가 얼마나 많이 사용됐는지 한 눈에 파악 가능
(1) 패키지 준비하기
- wordcloud 패키지 이용
- RColorBrewer 패키지 이용 (글자 색깔을 표현하는 데 사용) cf. RColorBrewer 패키지는 R에 내장되어 있으니 별도로 설치하지 않아도 됨
(2) 단어 색상 목록 만들기
- RColorBrewer 패키지의 brewer.pal()을 이용해 단어의 색깔을 지정할 때 사용할 색상 코드(Hex Color Code) 목록 생성
# Dark2 색상 목록에서 8개 색상 추출
pal <- brewer.pal(8, "Dark2")
(3) 난수 고정하기
- wordcloud()는 함수를 실행할 때마다 난수를 이용해 매번 다른 모양의 워드 클라우드를 생성함. 항상 동일한 워드 클라우드가 생성되도록 wordcloud()를 실행하기 전에 set.seed()로 난수를 고정
set.seed(1234)
(4) 워드 클라우드 만들기
- df_word 이용해 워드 클라우드 생성 (df_word는 단어와 단어가 사용된 빈도, 두 변수로 구성된 데이터 프레임)
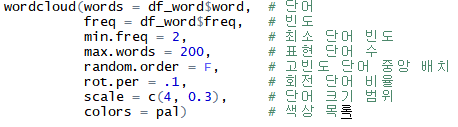
- 출력된 워드 클라우드는 많이 사용된 단어일수록 글자가 크고 가운데에 배치
- 덜 사용된 단어일수록 글자가 작고 바깥쪽에 배치되는 형태로 구성

(5) 단어 색상 바꾸기
pal <- brewer.pal(9, "Blues")[5:9] # 색상 목록 생성
set.seed(1234) # 난수 고정- 파란색 계열의 색상 목록을 만들어 빈도가 높을수록 진한 파란색으로 표현됨
+ 추가
★ 패키지를 로드했는데 에러 메시지가 출력된다면?
- 'Error : .onLoad failed in loadNamespace() for 'rJava'' 라는 에러 메시지가 출력됐다면 자바가 설치된 폴더의 경로를 설정하는 코드를 실행한 후 다시 패키지를 로드하세요. 설치 경로는 자바의 버전이나 OS에 따라 다를 수 있으니 'C:/Program Files/Java/' 에서 확인한 후 자신의 환경에 맞게 설정하세요.
# java 폴더 경로 설정
Sys.setenv(JAVA_HOME="C:/Program Files/Java/jre1.8.0_111/")
(출처; 가천대학교 컴퓨터공학과, 이영호 교수님)
(출처; 쉽게 배우는 R 데이터 분석, 김영우)
'Programming Language > R' 카테고리의 다른 글
| 12. 인터랙티브 그래프 (0) | 2019.05.31 |
|---|---|
| 11. 지도 시각화 (0) | 2019.05.31 |
| 08 그래프 만들기 (2) - 선 그래프, 상자 그림 (0) | 2019.05.29 |
| 08 그래프 만들기 (1) - 산점도, 막대 그래프 (0) | 2019.05.29 |
| 07. 데이터 정제하기 - 이상치 (0) | 2019.05.27 |




