상관분석(Correlation Analysis)이란?
- 두 연속 변수가 서로 관련이 있는지 검정하는 통계 분석 기법 (H0: 두 변수 간 관계 없다 / H1: 관계 있다)
상관계수(Correlation Coefficient)란?
- 상관분석을 통해 도출되고 상관계수를 통해 두 변수가 얼마나 관련되어 있는지, 관련성의 정도 파악 가능
- 상관계수는 0~1 사이의 값을 지니고 1에 가까울수록 관련성이 크다는 것을 의미
→ 상관계수가 양수: 정비례 관계
→ 상관계수가 음수: 반비례 관계
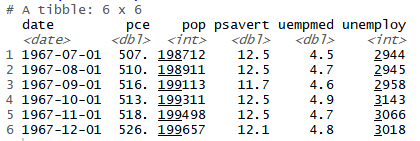
■ ggplot2 패키지의 economics 데이터를 이용해서 실업자 수와 개인 소비 지출의 상관관계 분석
- R에 내장된 cor.test()를 이용하여 상관분석
economics <- as.data.frame(ggplot2::economics)
cor.test(economics$unemploy, economics$pce)
① 실업자 수와 개인 소비 지출의 상관이 통계적으로 유의하다
- 출력 결과의 p-value를 계산하면 0.05 미만인 것을 알 수 있다.
② 'cor'
- 'cor'은 상관계수를 의미. 상관계수가 양수 0.61이므로, 실업자 수와 개인 소비 지출은 한 변수가 증가하면 다른 변수가 증가하는 정비례 관계임을 알 수 있다.
■ 상관행렬 히트맵 만들기
- 여러 변수의 관련성을 한 번에 보고자 할 경우, 모든 변수의 상관 관계를 나타낸 상관행렬(Correlation Matrix)를 만들고, 상관행렬을 보면 어떤 변수끼리 관련이 크고 적은지 파악할 수 있음.
1. cor()을 이용하여 상관행렬 만들기
- R에 내장된 mtcars 데이터를 이용할 예정 (mtcars는 자동차 32종의 11개 속성에 대한 정보를 담고 있는 데이터)
car_cor <- cor(mtcars) #상관행렬 생성
round(car_cor, 2) #소수점 셋째 자리에서 반올림해 출력
① 연비 별 실린더 수
- mpg(연비) 행과 cyl(실린더 수) 열이 교차되는 부분을 보면 상관계수가 -0.85임을 볼 수 있다. 상관계수가 음수면 반비례한다는 의미이므로 연비가 높을수록 실린더 수가 적은 경향이 있다는 것을 알 수 있다.
② 실린더 수 별 무게
- cyl(실린더 수)과 wt(무게)의 상관계수가 0.78이므로 정비례한다. 따라서 실린더 수가 많을수록 자동차가 무거운 경향이 있다는 것을 알 수 있다.
2. 상관행렬을 히트맵으로 만들기
- 여러 변수로 상관행렬을 만들면 변수들의 관계를 파악하기 쉽지 않음
- 상관행렬을 히트맵(heat map)으로 만들면 변수들의 관계 쉽게 파악 가능 (corrplot 패키지의 corrplot()을 이용)
cf) 히트맵(heat map): 값의 크기를 색깔로 표현한 그래프
install.packages("corrplot")
library(corrplot)
corrplot(car_cor)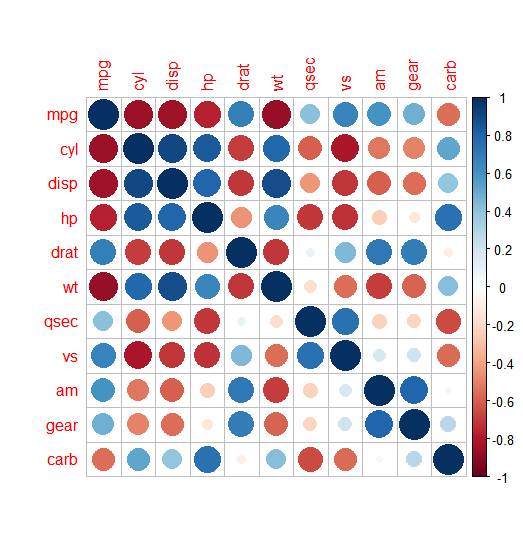
>> 상관계수가 클수록 원의 크기가 크고 색깔이 진하고, 상관계수가 양수면 파란색, 음수면 빨간색 계열로 표현되어 있음. 원의 크기와 색깔을 보면 상관관계 정도와 방향 쉽게 파악 가능
3. 그래프 형태 바꾸기
- corrplot()의 파라미터를 이용해 그래프 형태를 다양하게 바꾸는 것이 가능. method에 "number"를 지정하여 원 대신 상관계수가 표현되도록 설정 가능
corrplot(car_cor, method = "number")
4. 다양한 파라미터 지정
- 그래프 색깔을 바꾸기 위해 colorRampPalette()로 색상 코드 목록을 생성한 후 col 파라미터에 지정
col <- colorRampPalette(c("#BB4444", "#EE9988", "#FFFFFF", "#77AADD", "#4477AA"))
corrplot(car_cor,
method = "color", # 색깔로 표현
col = col(200), # 색상 200개 선정
type = "lower", # 왼쪽 아래 행렬만 표시
order = "hclust", # 유사한 상관계수끼리 군집화
addCoef.col = "black", # 상관계수 색깔
tl.col = "black", # 변수명 색깔
tl.srt = 45, # 변수명 45도 기울임
diag = F) # 대각 행렬 제외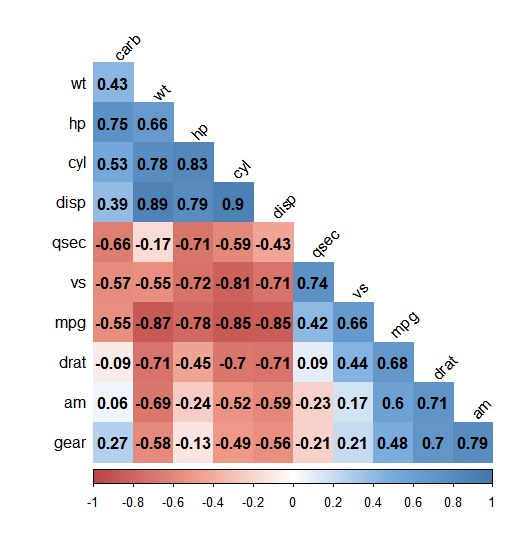
(참고자료: Visualize correlation matrix using correlogram: http://www.sthda.com/english/wiki/visualize-correlation-matrix-using-correlogram
Visualize correlation matrix using correlogram - Easy Guides - Wiki - STHDA
Statistical tools for data analysis and visualization
www.sthda.com
(출처; 가천대학교 컴퓨터공학과, 이영호 교수님)
(출처; 쉽게 배우는 R 데이터 분석, 김영우)
'Programming Language > R' 카테고리의 다른 글
| 13-1. t 검정 (두 집단의 평균 비교) (0) | 2019.06.01 |
|---|---|
| 12. 인터랙티브 그래프 (0) | 2019.05.31 |
| 11. 지도 시각화 (0) | 2019.05.31 |
| 10. 텍스트 마이닝 (0) | 2019.05.30 |
| 08 그래프 만들기 (2) - 선 그래프, 상자 그림 (0) | 2019.05.29 |