1. 데이터는 어떻게 생겼나? - 데이터 프레임 이해하기
*데이터 프레임(Data Frame)
- 가장 많이 사용하는 데이터 형태로, 행과 열로 구성된 사각형 모양의 표처럼 생김
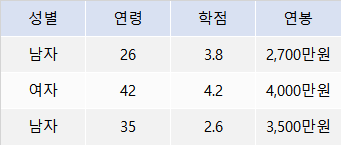
행을 보면 세 명의 자료임을 알 수 있고, 열은 성별, 연령, 학점, 연봉의 4가지 속성으로 되어 있음
>> 이 표는 '4개의 속성에 대한 3명의 자료로 구성된 데이터 프레임'이라고 할 수 있다.
'열'은 속성이다.
세로로 나열되는 열은 '속성'을 나타냄. 열은 '컬럼(Column)' 또는 '변수(Variable)'라고 불림
>> 만약, 어떤 데이터가 100가지 속성에 대한 정보를 가지고 있다면, 그 데이터는 100개의 컬럼 또는 100개의 변수를 가지고 있다고 표현할 수 있다.
'행'은 한 사람의 정보다.
가로로 나열되는 행은 각 사람에 대한 정보를 보여줌. 행은 '로(Row)' 또는 '케이스(Case)'라고 불림
행이 반드시 사람이어야 하는 건 아니지만, 무엇이든 하나의 단위가 하나의 행으로 구성될 수 있다. 예를 들어, 하나의 도시, 하나의 거래 내역, 하나의 웹 사이트 접속 기록도 행이 될 수 있다.
>> 만약, 어떤 데이터가 30명의 정보로 구성되어 있다면, 그 데이터는 30개의 Row 또는 30개의 Case를 가지고 있다고 표현할 수 있다.
데이터가 크다 = 행이 많다 또는 열이 많다
데이터를 분석하는 입장에서 봤을 때 행이 많은 것과 열이 많은 것 중 무엇이 더 중요할까?
>> 열이 많은 것이 더 중요하다. (행이 많은 것은 Computer Power로 해결)
>> 데이터의 양을 의미하는 행보다 데이터의 '다양성'을 의미하는 열이 많은 것이 분석의 측면에서 더 중요
행이 늘어나더라도 분석 기술의 측면에서는 별다른 차이가 생기지 않는다. 메모리를 늘려보고, 그래도 힘들다면 분산 처리 시스템을 구축하면 된다.
반면, 열이 많아지면 변수를 조합할 수 있는 경우의 수가 늘어난다. 예를 들어, 학점과 연봉의 관계는 전공이 무엇인지에 따라 다른 양상으로 나타날 수 있다. 여기에 출신지, 자격증, 성별, 직업군 등 수십 가지 변수가 추가되면 경우의 수가 기하급수적으로 늘어난다. 여러 변수의 영향을 동시에 고려할 수 있는 복잡한 분석 방법을 활용해야 할 필요성이 생기게 된다.
행이 많다 > 컴퓨터가 느려짐 > 고사양 장비 구축
열이 많다 > 분석 방법의 한계 > 고급 분석 방법 필요
2. 데이터 프레임 만들기 - 시험 성적 데이터 만들기
데이터 프레임은 데이터를 직접 입력해 만들 수도 있고, 외부의 데이터를 가져와 만들 수도 있다.
*데이터 직접 입력해서 데이터 프레임 만들기 (4명의 학생이 영어 시험과 수학 시험을 봤다고 가정)
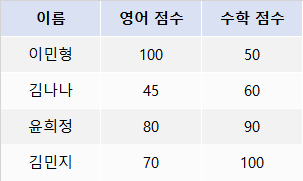
1. 변수 만들기
- 학생 4명의 영어 점수와 수학 점수를 담은 변수를 각각 만듦
english <- c(100, 45, 80, 70) # 영어 점수 변수 생성
math <- c(50, 60, 90, 100) # 수학 점수 변수 생성
2. 데이터 프레임 만들기
- 데이터 프레임을 만들 때는 data.frame( )을 이용 (데이터 프레임을 구성할 변수를 괄호 안에 쉼표로 나열)
#english, math로 데이터 프레임 생성해서 df_midterm에 할당
df_midterm <- data.frame(english, math)
df_midterm
## english math
## 1 100 50
## 2 45 60
## 3 80 90
## 4 70 100cf. 데이터 프레임의 이름을 정할 때 앞에 'Data Frame'의 약자인 'df'를 붙여 두면 다른 변수들과 구별하기 쉬움.
3. 생성된 데이터에 새로운 열 추가하기 (학생들의 반에 대한 정보를 추가해보기)
class <- c(1, 1, 2, 2)
df_midterm <- data.frame(class, english, math)
df_midterm
## class english math
## 1 1 100 50
## 2 1 45 60
## 3 2 80 90
## 4 2 70 100
4. 분석하기
- 데이터 프레임이 완성되면 분석해보기. mean( )을 이용해 전체 학생의 영어 점수와 수학 점수 평균을 구해볼 것
mean(df_midterm$english) #df_midterm의 english로 평균 산출
## [1] 73.75
mean(df_midterm$math) #df_midterm의 mathfh 평균 산출
## [1] 75mean ( ) 안에 입력된 df_midterm$english는 'df_midterm 데이터 프레임 안에 있는 english 변수'를 의미한다.
cf. 달러 기호($)는 데이터 프레임 안에 있는 변수를 지정할 때 사용한다.
5. 데이터 프레임 한 번에 만들기
- 위에서는 여러 변수를 각각 만든 후에 합치는 형태로 데이터 프레임을 만들었다. 이 방법 외에 data.frame( ) 안에 변수와 값을 나열해서 한 번에 만드는 방법도 있다.
df_midterm <- data.frame(class = c(1, 1, 2, 2),
english = c(100, 45, 80, 70),
math = c(50, 60, 90, 100))
df_midterm
## class english math
## 1 1 100 50
## 2 1 45 60
## 3 2 80 90
## 4 2 70 100cf. 코드가 길어질 경우에는 쉼표 뒤에서 엔터키를 눌러 다음 줄로 넘기는 것이 좋음. 전체적인 구조가 한 눈에 잘 들어오기 때문에 코드를 이해하기 쉽고 오류를 쉽게 찾을 수 있음.
3. 외부 데이터 이용하기 - 축적된 시험 성적 데이터 불러오기
직접 데이터를 입력하기보다 외부에서 생성된 데이터를 불러와 분석하는 경우가 더 많다.
* 데이터를 관리할 때 가장 많이 사용되는 엑셀 파일과 CSV 파일을 불러와 데이터 프레임을 만드는 방법 보기
1. 깃허브(bit.ly/doit_ra)에서 실습에 사용할 excel_exam.xlsx 파일 다운로드하기 (cf. 깃허브에서 실습 파일을 다운로드하는 방법은 블로그 내 ' ' 포스팅 참고)
2. 프로젝트 폴더에 엑셀 파일 삽입하기
- 데이터 파일을 불러오려면 현재 작업중인 프로젝트 폴더에 불러올 파일을 삽입해야한다. excel_exam.xlsx 파일을 프로젝트 폴더에 넣기
3. readx1 패키지 설치하고 로드하기
- 엑셀 파일을 불러오려면 엑셀 파일을 불러오는 기능을 제공하는 패키지를 이용해야 한다. readxl 패키지를 설치하고 로드한다. ( cf. readxl의 맨 뒷 글자는 소문자 엘 )
install.packages("readxl")
library(readxl)
4. 엑셀 파일 불러오기
- readxl 패키지에서 제공하는 read_excel( )을 이용해 엑셀 파일을 불러온다. read_excel( )은 엑셀 파일을 데이터 프레임으로 만드는 기능을 한다. 괄호 안에 양쪽에 큰따옴표와 함께 불러올 엑셀 파일명을 넣으면 되고, 확장자(.xlsx)까지 기입해야한다.
cf. R에서는 파일명을 지정할 때 항상 앞 뒤에 따옴표를 넣는다. 만약, 프로젝트 폴더가 아닌 다른 폴더에 있는 엑셀 파일을 불러오려면 파일 경로를 지정하면 된다. 경로를 지정할 때는 슬래시(/)를 사용한다.
df_exam <- read_excel("d:/easy_r/excel_exam.xlsx")
5. 분석하기
- mean( )을 이용해 전체 평균을 구할 수 있다.
엑셀 파일 첫 번째 행이 변수명이 아니라면?
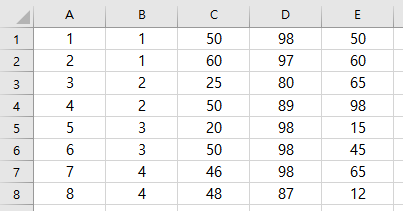
read_excel( )은 기본적으로 엑셀 파일의 첫 번째 행을 '변수명'으로 인식해 불러온다. 변수명 없이 첫 번째 행부터 바로 데이터가 시작되는 경우, 첫 번째 행의 데이터가 변수명으로 지정되면서 유실되는 문제가 발생한다.
df_exam_novar <- read_excel("excel_exam_novar.xlsx")
df_exam_novar
## 1 1__1 50 98 50__1
## 1 2 1 60 97 60
## 2 3 2 25 80 65
## 3 4 2 50 89 98
## 4 5 3 20 98 15
## 5 6 3 50 98 45
## 6 7 4 46 98 65
## 7 8 4 48 87 12출력 결과를 보면, 엑셀 파일 첫 번째 행을 변수명으로 인식해 원본과 달리 7행까지만 존재하는 문제가 발생한 것 보임.
>> col_names = F 파라미터를 설정하면 첫 번째 행을 변수명이 아닌 데이터로 인식해 불러오고, 변수명은 'X__숫자'로 자동 지정된다. (F는 대문자로 입력해야함)
df_exam_novar <- read_excel("excel_exam_novar.xlsx", col_names = F)
df_exam_novar
## X__1 X__2 X__3 X__4 X__5
## 1 1 1 50 98 50
## 2 2 1 60 97 60
## 3 3 2 25 80 65
## 4 4 2 50 89 98
## 5 5 3 20 98 15
## 6 6 3 50 98 45
## 7 7 4 46 98 65
## 8 8 4 48 87 12cf. R에는 참(TRUE)과 거짓(FALSE) 중 하나로 구성되는 논리형 벡터(Logical Vectors)라는 변수 타입이 있다. 논리형 벡터는 어떤 값이 참인지 거짓인지를 나타내는데, 여기서는 col_names = F의 F가 '거짓'을 의미한다. '열 이름(Column Name)을 가져올 것인가?'라는 질문에 '그렇지 않다'라는 답을 한 셈이다. <<논리형 벡터는 반드시 대문자 TRUE 또는 FALSE로 입력해야 하고, 앞글자만 따서 T 또는 F를 입력해도 된다.>>
엑셀 파일에 시트가 여러 개 있다면?
여러 개의 시트로 구성된 엑셀 파일을 불러올 경우 sheet 파라미터를 이용해 몇 번째 시트의 데이터를 불러올지 지정할 수 있다.
# 엑셀 파일의 세 번째 시트에 있는 데이터 불러오기
df_exam_sheet <- read_excel("excel_exam_sheet.xlsx", sheet = 3)
(출처; 쉽게 배우는 R 데이터 분석, 김영우)
'Programming Language > R' 카테고리의 다른 글
| 06. 자유자재로 데이터 가공하기 (0) | 2019.05.27 |
|---|---|
| 분석 도전! (쉽게 배우는 R 데이터 분석 p.160) (0) | 2019.05.26 |
| 05. 데이터 분석 기초 - 데이터 파악하기, 다루기 쉽게 수정하기 (0) | 2019.04.18 |
| 분석 도전! (쉽게 배우는 R 데이터 분석 p.123) (0) | 2019.04.04 |
| R이란? (0) | 2019.03.28 |