dplyr 패키지에 있는 함수 알아보기

dplyr 패키지 설치하기
library(dplyr)
filter() - 조건에 맞는 데이터만 추출하기
<1> dplyr 패키지를 로드한 후 csv_exam.csv 파일을 데이터 프레임으로 만들어 출력하기
exam <- read.csv("csv_exam.csv")
exam
<2> dplyr 패키지의 filter 함수를 이용하여 1반 학생들의 데이터만 추출하기
exam %>% filter(class==1)
<3> 같은 형식으로 2반 학생들의 데이터만 추출하기
exam %>% filter(class=2)<4> 변수가 '특정 값이 아닌 경우'에 해당하는 데이터 추출하기
exam %>% filter(class != 1) #1반이 아닌 학생만 추출
select() - 필요한 변수만 추출하기
<1> select() 이용하여 수학 점수만 추출하기
exam %>% select(math)
<2> select() 이용하여 여러 변수 추출하기
exam %>% select(class, math, english)
<3> 특정 변수 제외하기
exam %>% select(-english)
arrange() - 순서대로 정렬하기
<1> 오름차순으로 정렬하기
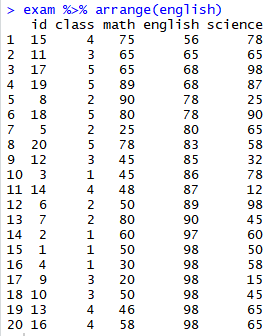
<2> 내림차순으로 정렬하기


mutate() - 파생변수 추가하기★
<1> 파생변수 추가하기

<2> 여러 파생변수 한 번에 추가하기
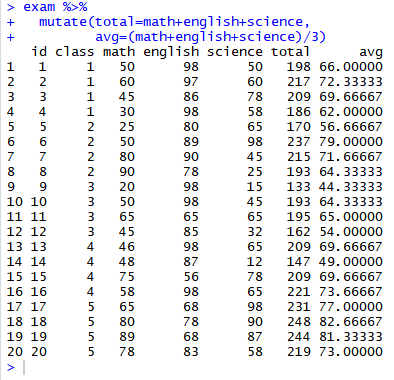
+

summarise() - 요약하기
** summarise 함수에는 연속형 변수만 들어갈 수 있다. (주로 group_by 함수와 같이 사용)
group_by() - 집단별로 나누기
** group_by 함수에는 범주형 변수만 들어갈 수 있다.

(출처; 쉽게 배우는 R 데이터 분석, 김영우)
'Programming Language > R' 카테고리의 다른 글
| 07. 데이터 정제하기 - 이상치 (0) | 2019.05.27 |
|---|---|
| 07. 데이터 정제하기 - 결측치 (0) | 2019.05.27 |
| 분석 도전! (쉽게 배우는 R 데이터 분석 p.160) (0) | 2019.05.26 |
| 05. 데이터 분석 기초 - 데이터 파악하기, 다루기 쉽게 수정하기 (0) | 2019.04.18 |
| 04. 데이터 프레임의 세계 (0) | 2019.04.18 |