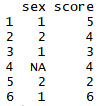
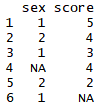
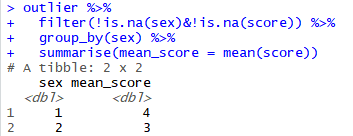
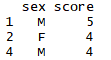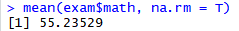2. 결측치 확인하기 - is.na() 사용하기 (결측치는 TRUE, 결측치가 아닌 값은 FALSE로 표시)
is.na(df)
is.na()를 사용해 결측치 확인
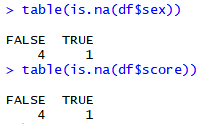
3. 데이터에 결측치가 몇 개 있는지 출력 - is.na()를 table()에 적용
table(is.na(df))
4. 결측치가 존재하는 변수 확인
■결측치 제거
1. 결측치 있는 행 제거하기 - '행'이므로 is.na()를 filter()에 적용
df %>% filter(is.na(score))
2. score의 값이 NA가 아닌 행들 출력
df %>% filter(!is.na(score))
3. 추출한 데이터로 데이터 프레임을 만들면 결측치가 없는 데이터가 생성됨
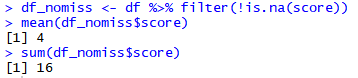
df_nomiss <- df %>% filter(!is.na(score)) #score 결측치 제거
mean(df_nomiss$score) #score 평균 산출
sum(df_nomiss$score) #score 합계 산출
결측치 없는 데이터
cf) na.omit() 을 이용하면 변수를 지정하지 않고 결측치가 있는 행을 한 번에 제거
df_nomiss2 <- na.omit(df)
na.omit()는 결측치가 하나라도 있으면 모두 제거하기 때문에 간편하게 쓸 수 있지만 분석에 필요한 데이터가 일부 손실된다는 단점이 있음. 따라서 filter()를 이용해 분석에 사용할 변수의 결측치만 제거하는 방식을 권함.
■ 함수의 결측치 제외 기능 이용하기
** mean()과 같은 수치 연산 함수들은 결측치를 제외하고 연산하도록 설정하는 na.rm 파라미터를 지원한다. na.rm을 TRUE로 설정하면 결측치를 제외하고 함수를 적용하기 때문에 결측치를 제거하는 절차를 건너뛰고 곧바로 분석할 수 있다. 하지만 모든 함수가 na.rm을 지원하는 것이 아니기 때문에 filter()로 결측치를 제거한 후에 함수를 적용하는 순으로 작업해야 한다.
1. na.rm() 파라미터 사용
mean(df$score, na.rm=T) #결측치를 제외하고 평균 산출
sum(df$score, na.rm=T) #결측치를 제외하고 합계 산출
2. summarise()도 na.rm 적용 가능
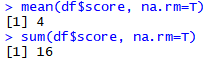
exam<-read.csv("csv_exam.csv")
exam[c(3, 8, 15), "math"] <- NA
summarise()에 mean()과 sum(), median() 함수를 불러온 다음 na.rm을 사용해서 결측치를 제외하고 값을 구함.