t 검정(t-test)란?
- 두 집단의 평균에 통계적으로 유의한 차이가 있는지 알아볼 때 사용하는 통계 분석 기법
- R에 내장된 t.test()를 이용해 t 검정 가능
■ ggplot2 패키지의 mpg 데이터를 이용해 compact 자동차와 suv 자동차의 도시 연비 t 검정을 수행
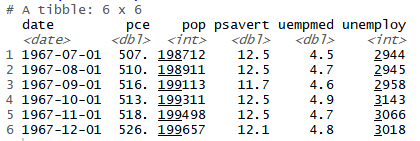
(1) mpg 데이터를 불러와 class, cty 변수만 남긴 뒤 class 변수가 "compact"인 자동차와 "suv"인 자동차를 추출
mpg <- as.data.frame(ggplot2::mpg)
library(dplyr)
mpg_diff <- mpg %>%
select(class, cty) %>%
filter(class %in% c("compact","suv"))
head(mpg_diff)
table(mpg_diff$class)
(2) t.test()를 이용해 t 검정
- 추출한 mpg_diff 데이터를 지정하고, ~ 기호를 이용해 비교할 값인 cty(도시 연비) 변수와 비교할 집단인 class(자동차 종류) 변수 지정
- t 검정은 비교하는 집단의 분산이 같은지 여부에 따라 적용하는 공식이 다름. (여기서는 집단 간 분산이 같다고 가정하고 var.equal 에 T를 지정)
t.test(data = mpg_diff, cty ~ class, var.equal = T)
① 출력된 t 검정 결과에서 'p-value'가 유의확률을 의미
(블로그 좌측 [Probability $ Statistics >> Lecture Summary] 의 '통계적 가설 검정이란?' 포스팅 참고)
- 일반적으로 유의확률 5%를 판단 기준으로 삼고, p-value가 0.05 미만이면 '집단 간 차이가 통계적으로 유의하다'고 해석. 실제로는 차이가 없는데 이런 정도의 차이가 우연히 관찰된 확률이 5%보다 작다면, 이 차이를 우연이라고 보기 어렵다는 결론. 'p-value < 2.2e - 16'은 유의확률이 2.2*10^-16 보다 작다는 의미이므로 여기서 p-value가 0.05보다 작다는 의미이다.
따라서 이 분석 결과는 'compact 와 suv 간 평균 도시 연비 차이가 통계적으로 유의하다'고 해석할 수 있다.
② 'sample estimates'
- 'sample estimates' 부분을 보면 각 집단의 cty 평균이 나타나 있음. "compact"는 20인 반면, "suv"는 13이므로, "suv"보다 "compact"의 도시 연비가 더 높다고 할 수 있음
(출처; 가천대학교 컴퓨터공학과, 이영호 교수님)
(출처; 쉽게 배우는 R 데이터 분석, 김영우)
'Programming Language > R' 카테고리의 다른 글
| 13-2. 상관분석 (두 변수의 관계성 분석) (0) | 2019.06.01 |
|---|---|
| 12. 인터랙티브 그래프 (0) | 2019.05.31 |
| 11. 지도 시각화 (0) | 2019.05.31 |
| 10. 텍스트 마이닝 (0) | 2019.05.30 |
| 08 그래프 만들기 (2) - 선 그래프, 상자 그림 (0) | 2019.05.29 |