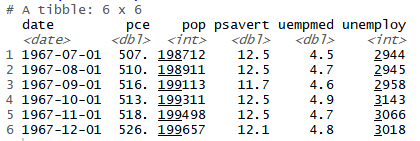
작년 하반기부터 일부 기업에서 시범적으로 AI면접을 도입하기 시작했다. 작년에는 부산은행, 경동나비엔, 대한송유관공사, 오리온 등 몇몇 회사가 AI면접을 도입했었다고 한다. AI 면접에서는 간단한 자기소개와 장, 단점을 말해보라는 기본적인 질문부터 여러 가지 상황에 따른 돌발 질문에 답하게 하는 등 여러 가지 타입의 문항이 있다고 한다. 심지어 하노이 탑과 같은 간단한 온라인 게임도 있다.
인공지능 면접은 장점과 단점이 동일하다. 인공지능 채용 시스템의 가장 큰 장점은 인간의 주관이 개입되지 않는다는 점이다. 객관적인 데이터로만 평가하니 주관적인 감정이 평가에 들어가지 않는 것이다. 특히 한국 사회에서 정말 민감한 채용 비리와 같은 문제가 인공지능 채용에 관심을 갖게 하는 이유 중 하나일 것이다.
단점은 현재 주어진 데이터에만 기반을 두고 채용을 결정하기 때문에 향후 성장 가능성에 대한 고려가 없다는 것이다. 또한 내가 AI 면접을 본다고 생각하면 면접 과정에서 사람이 아닌 PC를 보고 답하는 방식에 대해 거부감이 생길 것 같다.
(참고: str_replace_all()에 사용된 기호 \\W는 특수문자를 의미하는 '정규 표현식'. 정규 표현식을 이용하면 문장의 내용 중 이메일 주소, 전화 번호처럼 특정한 규칙으로 되어 있는 부분을 추출 가능)
■ 가장 많이 사용된 단어 알아보기
(1) 명사 추출하기
- KoNLP의 extractNoun()를 이용하면 문장에서 명사 추출 가능
- 명사를 보면 문장이 무엇에 대한 내용인지 파악 가능
extractNoun("대한민국의 영토는 한반도와 그 부속도서로 한다")
## [1] "대한민국" "영토" "한반도" "부속도서" "한"
(2) 빈도표 만들기
- 빈도표는 테이블(table) 형태이므로 다루기 쉽도록 데이터 프레임으로 변환하고 변수명을 수정
# 가사에서 명사 추출
nouns <- extractNoun(txt)
# 추출한 명사 list를 문자열 벡터로 변환, 단어별 빈도표 생성
wordcount <- table(unlist(nouns))
# 데이터 프레임으로 변환
df_word <- as.data.frame(wordcount, stringsAsFactors = F)
# 변수명 수정
df_word <- rename(df_word, word = Var1, freq = Freq)
(참고: extractNoun()은 출력 결과를 리스트 형태로 반환. table(unlist(nouns))는 리스트로 되어 있는 nouns를 빈도 테이블로 변환하는 기능을 함.)
(3) 자주 사용된 단어 빈도표 만들기
- 한 글자로 된 단어는 의미가 없는 경우가 많기 때문에 nchar()를 이용해 두 글자 이상으로 된 단어만 추출
df_word <- filter(df_word, nchar(word) >= 2)
(4) 상위 20개 단어 추출
- 빈도 순으로 정렬한 후 상위 20개 단어 추출
top_20 <- df_word %>%
arrange(desc(freq)) %>%
head(20)
top_20
## word freq
## 1 you 89
## 2 my 86
## 3 YAH 80
## 4 on 76
## 5 하나 75
.
.
.
- 텍스트가 힙합 가사이기 때문에 you, my, YAH 같은 영단어가 많이 사용됐다는 것을 알 수 있음
■ 워드 클라우드 만들기
워드 클라우드(Word cloud)란?
- 단어의 빈도를 구름 모양으로 표현한 그래프
- 단어의 빈도에 따라 글자의 크기와 색깔이 다르게 표현되기 때문에 어떤 단어가 얼마나 많이 사용됐는지 한 눈에 파악 가능
(1) 패키지 준비하기
- wordcloud 패키지 이용
- RColorBrewer 패키지 이용 (글자 색깔을 표현하는 데 사용) cf. RColorBrewer 패키지는 R에 내장되어 있으니 별도로 설치하지 않아도 됨
(2) 단어 색상 목록 만들기
- RColorBrewer 패키지의 brewer.pal()을 이용해 단어의 색깔을 지정할 때 사용할 색상 코드(Hex Color Code) 목록 생성
# Dark2 색상 목록에서 8개 색상 추출
pal <- brewer.pal(8, "Dark2")
(3) 난수 고정하기
- wordcloud()는 함수를 실행할 때마다 난수를 이용해 매번 다른 모양의 워드 클라우드를 생성함. 항상 동일한 워드 클라우드가 생성되도록 wordcloud()를 실행하기 전에 set.seed()로 난수를 고정
set.seed(1234)
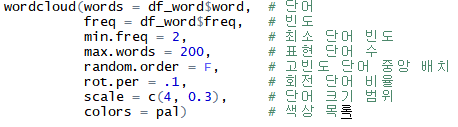
(4) 워드 클라우드 만들기
- df_word 이용해 워드 클라우드 생성 (df_word는 단어와 단어가 사용된 빈도, 두 변수로 구성된 데이터 프레임)
- 출력된 워드 클라우드는 많이 사용된 단어일수록 글자가 크고 가운데에 배치
- 덜 사용된 단어일수록 글자가 작고 바깥쪽에 배치되는 형태로 구성
(5) 단어 색상 바꾸기
pal <- brewer.pal(9, "Blues")[5:9] # 색상 목록 생성
set.seed(1234) # 난수 고정
- 파란색 계열의 색상 목록을 만들어 빈도가 높을수록 진한 파란색으로 표현됨
+ 추가
★ 패키지를 로드했는데 에러 메시지가 출력된다면?
- 'Error : .onLoad failed in loadNamespace() for 'rJava'' 라는 에러 메시지가 출력됐다면 자바가 설치된 폴더의 경로를 설정하는 코드를 실행한 후 다시 패키지를 로드하세요. 설치 경로는 자바의 버전이나 OS에 따라 다를 수 있으니 'C:/Program Files/Java/' 에서 확인한 후 자신의 환경에 맞게 설정하세요.
# java 폴더 경로 설정
Sys.setenv(JAVA_HOME="C:/Program Files/Java/jre1.8.0_111/")